

Everyone likes a good mystery, so here is one—but instead of the expected murder and mayhem, this caper involves social media, the Google box, local news outlet reporting, and Virginia Chronicle.
On Monday, October 21, I was making my weekly review of the array of Google Analytics data for Virginia Chronicle, the Library of Virginia’s online newspaper database.
Usually, I look at the number of sessions per day, which in recent years has ranged from 350 to 750. This past summer, no surprise, showed some of the most robust numbers ever for “VA Chron.” With the COVID pandemic at full force, it may be that those stuck at home decided, okay, time to stop binge watching Breaking Bad and Peaky Blinders and get back to searching the newspaper database for the genealogy project that’s begging for attention.
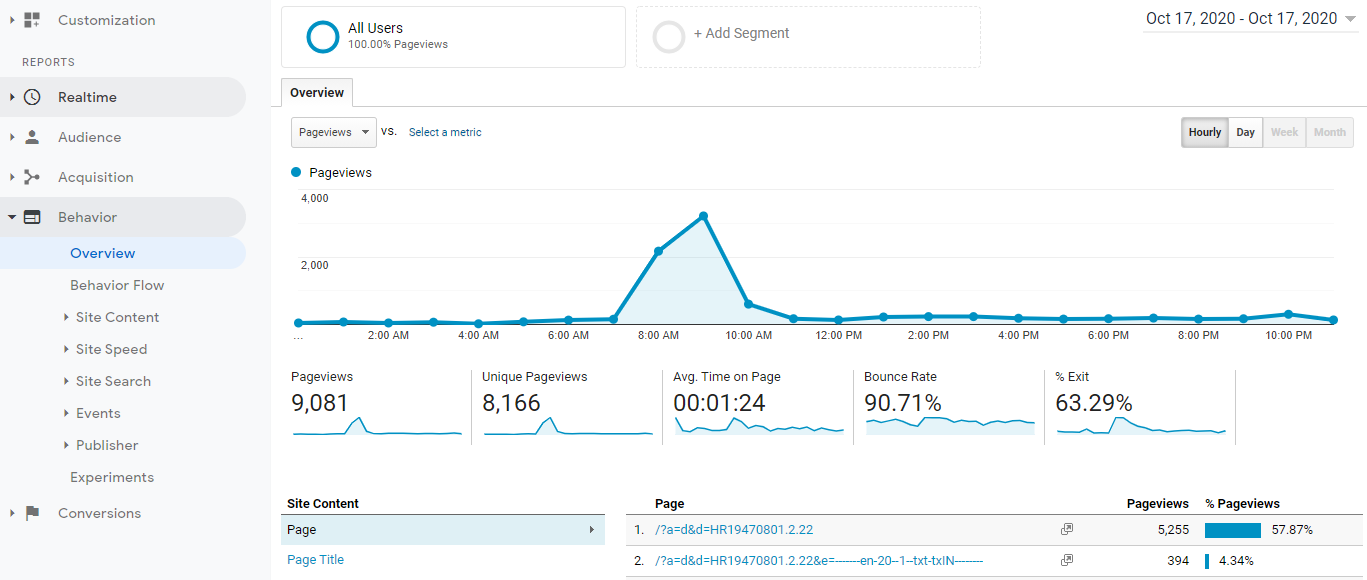
However, on this day, I was staring at the screen for a full 60 seconds trying to make sense of the sessions report for 17 October 2020—Virginia Chronicle registered almost 6,000 visits! The spike was Mount Everest compared to the previous and following days.

Google Analytics report for Virginia Chronicle showing October 17 spike.
What was going on here? Looking back through September and October, it appeared to be business as usual with visits and session statistics that made sense, but Saturday, October 17, was unlike anything I had seen before, which includes years of analytical reports.
My first thought: was it larceny? That is, was an online commercial newspaper publisher trying to “scrape” the PDFs from the Virginia Chronicle site? Not an easy feat given the added levels of security that require registration to download PDFs (and access to other features), preventing someone or some entity grabbing large batches of PDFs and plopping them down onto another site. Unlikely, but it has happened before—and once bitten, twice shy.
I immediately emailed Richard Managh, our project design liaison at DL Consulting, the New Zealand company that created the software in which over 1.2 million pages of Virginia and West Virginia newspapers currently reside.
I had to pause and marvel that I am communicating with a colleague in New Zealand who gets back to me once he gets to the office (which is the next day in NZ), and then gets busy accessing the available tools and resources to assist in solving the riddle of the 6,000.
In an edited exchange of emails, we have the following from our operative, Mr. Managh:
Errol, this is basically how our investigation went:
First we checked specifically for downloads of PDFs, because you queried larceny, but there weren’t a significant amount (of downloads) on that day.
We checked if the traffic was from a bot, but normally that would not show up in Google Analytics because Google Analytics uses javascript to record hits and because bots typically don’t run javascript, they consequently don’t show up in Google Analytics hits.
We then looked into the nature of the hits in Google Analytics, and they began to look like normal human/user behavior. If a site suddenly receives a large spike in web traffic from normal users – i.e. not bots – that suggests Virginia Chronicle may have been linked to or from a popular blog, website, or from some news network.
We noticed that the source of the hits were mostly organic searches. In other words, Google searches.
At this point, we looked at the exact time of day of the hits and it was mostly between 8am and 11am on that Saturday (October 17).
Checking the location of the users of the hits, we noticed there seemed to be a large number of users from Harrisonburg, VA.

Performance report showing search terms used to reach Virginia Chronicle during the October 17 spike.

Analytics data showing the October 17 spike came largely from users in the Harrisonburg (Va.) area.
We took a look at the Virginia Chronicle newspaper article that comprised most of the hits and after scanning the pages, there appeared to be coverage of some sort of disaster…also in Harrisonburg.
Finally, at this point the puzzle pieces started to come together.

The spike in activity took place just after an explosion near Harrisonburg (Va.) on October 17, 2020.
We decided to search Harrisonburg in Google which revealed news of an explosion. We looked at whether the time of the explosion matched the time of the hits, and it did!
That led us to google Harrisonburg explosion to see if the article on Virginia Chronicle from 1947 would come up as it appeared to have the most hits, and surprisingly it did, and yet it was near the bottom of the page of search results.
News reports from the local outlets dominated the array of Google search results.

HIGHLAND RECORDER banner, 1 August 1947
Screenshot from Virginia Chronicle.
At this point, I mused, if the Virginia Chronicle search result lingered at the bottom of the page, why would this search result lead to so many hits in Virginia Chronicle? It’s no surprise that people generally click on only the top results.
Richard almost psychically answered my question as we exchanged emails:
On Saturday people in Harrisonburg experienced first-hand or quickly heard about a major explosion, and then began to search Google to find out more. Many of them ended up looking at a newspaper article on Virginia Chronicle from 1947 that included a report of an explosion in Harrisonburg.
It then dawned on us that at the time of the explosion, these news articles did not yet exist, and so the Virginia Chronicle newspaper article would probably at that time have been near the top of the search results, which seems to have been the big component of why this big spike in visits happened.
Two explosions in Harrisonburg, separated by 73 years, were brought together as local citizens scrambled to their computers to find answers to a very loud blast they had just heard (and felt).
And that’s how you get 6,000 hits in one day. Actually, 6,000 in a matter of minutes.
Case closed.

HIGHLAND RECORDER article about the July 1947 explosion in Harrisonburg, with search terms highlighted.
Screenshot from Virginia Chronicle.



